

W3Cschool
恭喜您成為首批注冊用戶
獲得88經(jīng)驗值獎勵

Mycat2 索引字段分析

Mycat2是分庫分表型數(shù)據(jù)庫(中間件),具有邏輯庫,邏輯表概念,其中對于分片表類型,使用特定的規(guī)則組織'行數(shù)據(jù)'在多個物理表中存儲.而SQL查詢分片表的時候,正確使用謂詞,Mycat2分析出僅需掃描的物理表,則可在執(zhí)行階段大大減少需要使用的連接,IO耗時,因為謂詞不符合數(shù)據(jù)分布,查詢的結(jié)果集就是空的.(v1.18提供索引字段分析)
在分庫分表數(shù)據(jù)庫中,使用不同的數(shù)據(jù)定位字段減少掃描的范圍,它們是分表鍵,分庫鍵,全局二級索引等.下推它們有著索引字段分析相似的功能.索引字段分析在數(shù)據(jù)庫中至關(guān)重要.通常我們判斷SQL能否使用哪種掃描數(shù)據(jù)方式就可以大致判斷SQL的查詢效率,對于分庫分表中間件來說,盡可能減少掃描范圍,甚至嚴(yán)格保證掃描的存儲節(jié)點只有一個存儲節(jié)點才是正確的用法.
索引字段分析的工作過程
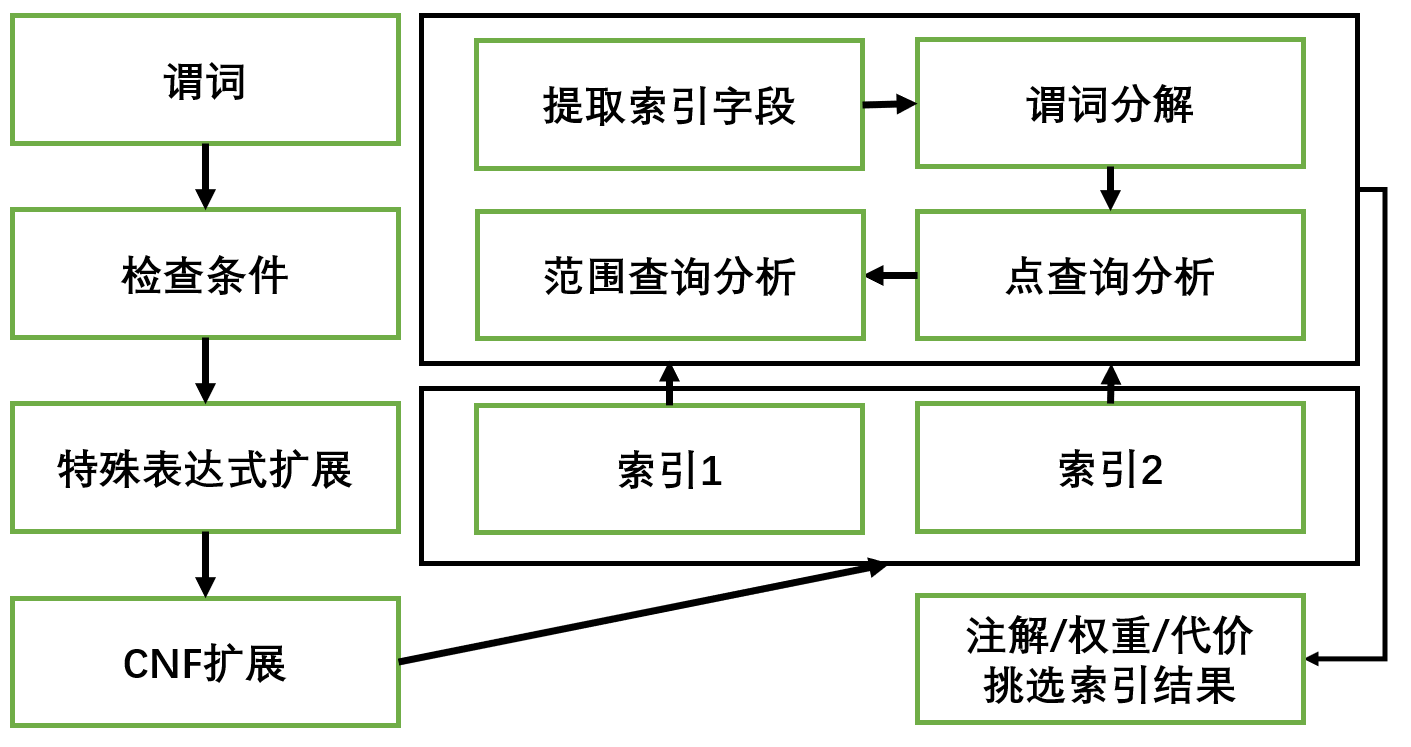
非DNF檢查
首次,優(yōu)化器會提取下壓到表掃描算子上的謂詞,并把他們做disjunction(DNF)轉(zhuǎn)換,試圖得到一組or相鄰的表達(dá)式,如果該表達(dá)式的數(shù)量是1,則表示該組表達(dá)式?jīng)]有or運算,則可繼續(xù)進行謂詞分析,否則不滿足謂詞分析約束.

RexNode:{id = 1 or id = 2} → List<RexNode>[{id = 1},{id = 2}]
即
W=P1∨P2∨P3∨...Pn
特殊表達(dá)式擴展
其次,對謂詞表達(dá)式擴展.在這里我們可以把一些特殊意義的表達(dá)式擴展,比如
id between 1 and 3 → 1 <= id and id <= 3
這樣的好處與括號()表達(dá)優(yōu)先級差不多,表示該表達(dá)式是一個整體,它們不被CNF/DNF影響.
CNF擴展
然后,對謂詞進行CNF分析.得到一組and相鄰的表達(dá)式.
RexNode:{id = 1 and id = 2} → List<RexNode>[{id = 1},{id = 2}]
即
W=P1^P2^P3^...Pn
索引應(yīng)用
因為分片表可能存在多個索引信息,它們依次應(yīng)用CNF擴展的結(jié)果.
提取索引字段
使用謂詞檢查語法檢查and表達(dá)式中的每個表達(dá)式,提取scan_binary_expr這個層次的語法樹,檢查其中的字段是否索引字段,把它們轉(zhuǎn)換成謂詞節(jié)點并依照遍歷順序收集起來,與常規(guī)的解析器不同不符合語法的部分不會發(fā)生異常,直接跳過.
謂詞檢查語法
and_expr : scan_binary_expr 'AND' scan_binary_exprscan_binary_expr : left_expr '=' right_expr | left_expr '<' right_expr | left_expr '>' right_expr | left_expr '<=' right_expr | left_expr '>=' right_expr | right_expr '=' left_expr | right_expr '<' left_expr | right_expr '>' left_expr | right_expr '<=' left_expr | right_expr '>=' left_expr | ...right_expr : LITERAL | DYNAMIC_PARAM | CAST LITERALleft_expr : COLUMN | cast_exprcast_expr : CAST right_expr | CAST left_expr
謂詞分解
將謂詞分解為等值查詢,范圍查詢,剩余查詢?nèi)N類型
type = 'famliy' and score < 60 and score >=0
即


而索引謂詞分析的目標(biāo)則是提取 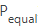 或者
或者 
對于相同的字段,為了減少掃描范圍,顯然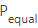 總是比
總是比  更優(yōu)
更優(yōu)
一些規(guī)約
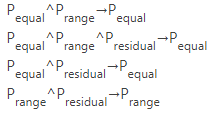
索引最左匹配原則
做左到右盡可能掃描指定的運算符,遇到不是需要的運算符則停止掃描
分解點查詢謂詞節(jié)點
應(yīng)用索引最左匹配原則(做左到右盡可能掃描=的條件),檢查是否點查詢并把它們轉(zhuǎn)換成點查詢條件組,即可下推索引謂詞組,而不能轉(zhuǎn)換的謂詞節(jié)點構(gòu)成剩余條件組.
分解范圍查詢謂詞節(jié)點
與分解點查詢謂詞節(jié)點相似,范圍查詢也是應(yīng)用索引最左匹配原則(做左到右盡可能掃描>=,>等條件),檢查是否點查詢并把它們轉(zhuǎn)換成上界/下界條件組,即可下推索引謂詞組,而不能轉(zhuǎn)換的謂詞節(jié)點構(gòu)成剩余條件組.這里的上下界條件組中每個條件不具有between語義.上界與下界是獨立的條件.
score < 60 and score >=0 → [{score <60},{score >= 0}]
注解選擇索引結(jié)果
最后,可能得到一組索引信息分析得到的結(jié)果,如果謂詞分析器帶有了注解要求的索引,在結(jié)果中有,則返回它的索引結(jié)果.(所以錯誤的注解可能導(dǎo)致無法使用真正有效的索引)
最終的索引分析結(jié)果
對它們的權(quán)重進行排序,返回權(quán)重最高的索引信息.
索引結(jié)果轉(zhuǎn)換至分片條件
每個索引謂詞都有它們的類型,比如點查詢或者范圍查詢.對于點查詢,可以直接調(diào)用分片算法的點查接口就可以得到存儲節(jié)點的信息.而對于范圍查詢,我們可以檢查上界下界條件,并進一步把它們轉(zhuǎn)換成查詢區(qū)間,然后調(diào)用分片算法的范圍查詢接口即可.
鍵的優(yōu)先級
索引結(jié)果可能存在以下情況
一個索引結(jié)果有多個不同的字段
多個索引結(jié)果,這里僅討論多個索引結(jié)果之間如何挑選最優(yōu)的.
如果一個謂詞中出現(xiàn)多個字段,而這些字段中有多個是可以定位數(shù)據(jù)分布,但是它們的執(zhí)行代價,掃描范圍可能相同也可能不相同,有些需要額外的IO,連接才可以完成數(shù)據(jù)定位.這個情況下,我們需要定義這些定位數(shù)據(jù)分布的索引字段之間的優(yōu)先級,從中選擇最有效的字段來定位數(shù)據(jù).一般來說,存在以下規(guī)則.
等值查詢總是比范圍查詢更優(yōu)
分表鍵總是比分庫鍵更優(yōu)
...
對于難以判斷那種索引更優(yōu)或者索引性能隨著數(shù)據(jù)量改變的情況,可以使用代價分析判斷.
- 內(nèi)容錯誤
- 更新不及時
- 鏈接錯誤
- 缺少代碼/圖片示列
- 太簡單/步驟待完善
- 其他
Copyright©2021 w3cschool編程獅|閩ICP備15016281號-3|閩公網(wǎng)安備35020302033924號
違法和不良信息舉報電話:173-0602-2364|舉報郵箱:jubao@eeedong.com



更多建議: